
Le support du standard SQL/MED a été introduit dans PostgreSQL 9.1 (2011). Quatre ans plus tard, nous avons maintenant plus de 70 Foreign Data Wrappers (FDW) disponibles pour lire et écrire sur tout type de moteur de stockage: base Oracle ou MongoDB, fichiers XML, cluster Hadoop, dépot Git, Twitter, etc. etc. etc.

Il y a quelque jours, pendant le FOSDEM j’ai assisté à la conférence de mon collègue Ronan Dunklau intitulée Foreign Data Wrappers in PostgreSQL : Where are we now ? Ronan est l’auteur de l’extension multicorn et pendant sa présentation je me suis rappelé à quel point multicorn est probablement le projet le plus sous-estimé de la communauté PostgreSQL. En guise d’exercice, j’ai commencé à compter tous les FDW que je connaissais… et j’ai rapidement réalisé qu’il y en avait trop pour ma mémoire de poisson rouge !
Du coup, je suis retourné sur la liste de FDW du wiki PostgreSQL. J’ai commencé à mettre à jour et reformatter le catalogue de tous les wrappers existants et j’ai abouti à une liste de plus de 70 wrappers pour PostgreSQL…
Quelques leçons à en tirer
Pendant cet inventaire, j’ai découvert quelques points intéressants:
-
Tous les SGBD majeurs sont couverts à l’exception de DB2. Bizarrement DB2 est aussi le seul SGBD majeur ayant une implémentation du standard SQL/MED. Difficile de dire si ces deux faits sont liés ou pas…
-
Un tiers des FDW sont écrits en Python et basés sur Multicorn. Les autres sont des wrappers “natifs” écrits en C. Assez logiquement les wrappers en C sont prvilégiés pour les connecteurs de SGBD (ODBC, Oracle, etc.) pour des raisons de performance. En parallèle Multicorn est utilisé majoritairement pour les interroger des web services (S3 storage,RSS files, etc.) et des formats de données specifiques (fichiers de genotype, GeoJSON, etc.)
-
Je ne pense pas que c’était le but initial mais les Foreign Data Wrappers sont aussi un vecteur d’innovation. Certains connecteurs sont détournés de leur usage premier pour développer de nouvelles fonctionnalités. Par exemple, CitusDB a publié une base de données orientée colonnes basée sur un FDW, d’autres wrappers vont dans des directions encore plus exotiques comme la collecte de stats au niveau OS, de l’accéleration GPU pour les seq scans ou un moteur traitement parallèle de requêtes… La plupart de ces projets ne conviennent pas pour de la production bien sur. Cependant cela démontre qu’il est aisé d’implémenter un PoC et à quel point cette technologie est versatile.
-
Le réseau de distribution PGXN semble plutot méconnu. Seulement 20% des wrappers sont disponibles via PGXN. Ou peut-être que les développeurs sont trop paresseux pour créer un paquet pour leur extension ?
-
Le succès de l’implémentation d’ SQL/MED dans PostgreSQL a toutefois des inconvénients. A vue de nez, il y aura plus de 100 wrappers disponibles à la fin 2015. Pour certaines sources de données comme mongodb ou LDAP, il y a déjà plusieurs wrappers différents, sans parler de la cohorte de connecteurs Hadoop :) Sur le long terme, les utilisateurs de PostgreSQL auront du mal à déterminer quels sont les wrappers maintenus et lesquels sont abandonnés… La page de wiki est une tentative pour répondre à cette question mais il y a surement d’autres solutions pour fournir des informations précises et exhaustives aux utilisateurs. Peut-être qu’il faudrait un data Wrapper qui pourrait lister tous les data wrappers :)
The next big thing : IMPORT FOREIGN SCHEMA
De plus, il reste une limitation majeure à l’implémentation actuelle : les meta données. Actuellement, il n’y a pas de moyen simple d’utiliser les (éventuelles) capacités d’introspection de la source de données distante. En clair : vous devez créer toutes vos tables externes une par une. Lorsque l’on veut se connecter à toutes les tables d’une base distantes, c’est répétitif et il y a un risque d’erreurs. Si vous vous connectez à une base PostgreSQL distante, vous pouvez utiliser des astuces mais clairement c’est une tache qui devrait être faite au niveau du connecteur lui-même.
Heureusement voici la commande IMPORT FOREIGN SCHEMA ! Cette nouvelle fonctionnalité a été écrite par Ronan Dunklau, Michael Paquier et Tom Lane. Vous pouvez lire une démo rapide sur le blog de Michael. Cette commande sera disponible dans la version 9.5.
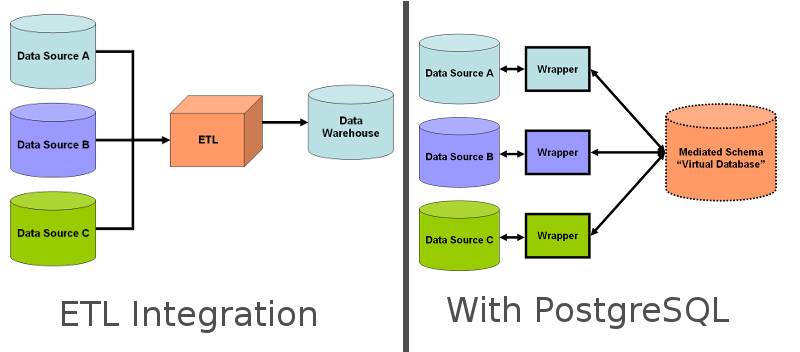
C’est une amélioration énorme ! Avec cet IMPORT et les douzaines de wrappers disponibles, PostgreSQL est en passe de devenir une plateforme d’intégration de données unique et le besoin d’utiliser des outils d’ETL externes devient de plus en plus faible.
Liens :
EDIT : Merci à Eric Pommereau et Guénolé Marquier pour la relecture !
blog comments powered by Disqus